Model-Based Diffusion for Trajectory Optimization
核心思想
模型引导扩散 (MBD) 创新性地将已知的模型信息(动力学、成本、约束)直接整合进扩散模型的评分函数计算过程中。它不依赖于大规模演示数据来学习评分函数,而是在每个去噪步骤实时地通过一个基于模型模拟和评估的计算流程来估算评分函数的值,从而指导轨迹生成。

背景:扩散模型与轨迹优化
传统的扩散模型(可以称之为“模型无关扩散” - Model-Free Diffusion, MFD)通常像个“黑箱”,主要依赖大量高质量的数据来学习如何生成轨迹。这就带来几个问题:
- 数据依赖: 获取理想的数据(比如专家操作、最优轨迹)成本高昂,有时甚至不现实。
- 泛化困难: 模型学到的是“数据长啥样”,但不理解背后的物理规律。换个机器人(动力学变了)或新任务(目标、约束变了),模型可能就“懵了”。
- 信息浪费: 在很多 TO 问题中,我们其实是知道系统的动力学模型、成本函数和约束条件的。MFD 方法通常没有直接利用这些宝贵的“模型信息”。
这就好比教一个人开车,MFD 是让他看无数老司机的录像,而 MBD 是直接给他一本包含车辆手册、交规和导航地图的“说明书”。
为了解决上述问题,MBD不再依赖数据,而是直接利用已知的领域信息来指导扩散过程,生成满足要求的轨迹。
前向扩散(加噪)
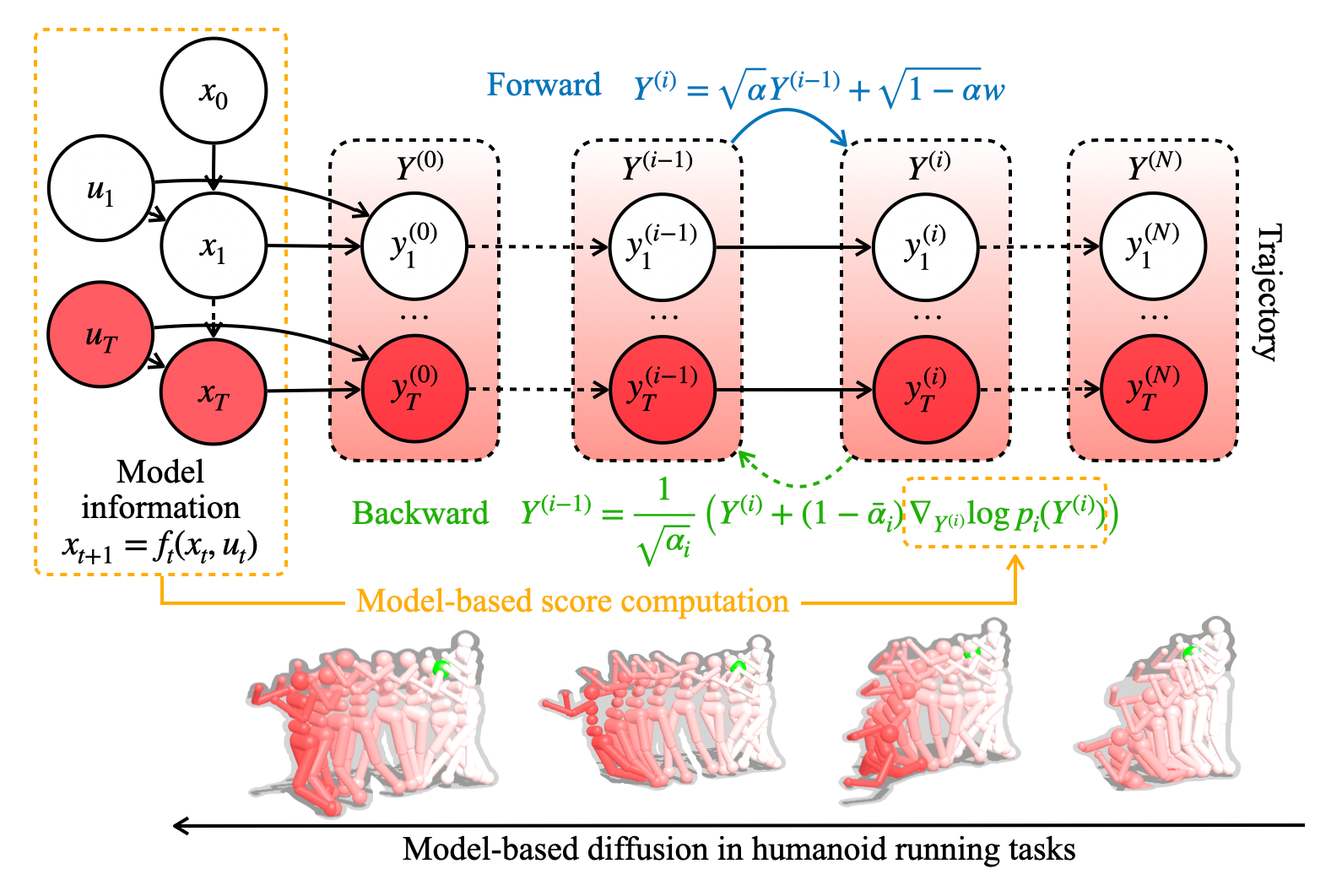
- 从原始的“干净”数据
Y(0)(在 MBD 中是理想的轨迹 )开始。 - 逐步、多次地添加少量高斯噪声。
- 最终得到一个纯粹的噪声分布
Y(N)(通常是标准高斯分布)。 - 关键在于,给定
Y(0),任何中间步骤Y(i)的分布是可以直接计算的(基于Y(i) = √ ̄αᵢ * Y(0) + √(1 - ̄αᵢ) * ε)。
反向去噪
- 从纯噪声
Y(N)开始。 - 逐步地、迭代地移除噪声,逆转前向过程。
- 最终生成一个符合目标数据分布的样本
Y(0)在 MBD 中是优化后的轨迹)。 - 这个过程的核心是估计每一步应该如何去噪,这等价于估计评分函数
∇ log p(Y(i))。
类比: 就像雕刻家从一块大理石(噪声
Y(N))开始,逐步凿掉多余的部分(去噪),最终显露出内在的雕像(目标轨迹Y(0))。反向过程的关键就是知道每一步该“凿掉”哪里(评分函数的指引)。
关键:评分函数 (Score Function)
MBD 与传统扩散模型的主要区别在于如何实现反向去噪中的核心步骤——估计评分函数 ∇ log p(Y(i)):
评分函数 ∇ log p(Y(i)) 是反向去噪过程的“导航仪”。它告诉我们在当前的噪声样本 Y(i) 处,应该往哪个方向移动才能更接近目标数据的分布。
- 传统 MFD (Model-Free Diffusion) 做法:
- 通常需要一个神经网络(Score Network)。
- 依赖大量数据训练这个网络来近似
∇ log p(Y(i))。 - 数据是关键,模型信息通常不直接使用。
- MBD (Model-Based Diffusion) 做法:
- 评分函数的理论定义不变。
- 不训练网络来拟合评分函数。
- 利用已知的模型信息(动力学
f、成本J、约束g)通过一个计算流程在每个时间步i实时估算出∇ log p(Y(i))的值。
即MBD 在反向过程中获取“雕刻指导”(评分函数)的方式是基于模型计算,而不是基于数据学习。
MBD 如何“计算”评分函数?
这是 MBD 的核心机制。它设计了一个巧妙的计算步骤,在不去学习的情况下,得到评分函数的值。
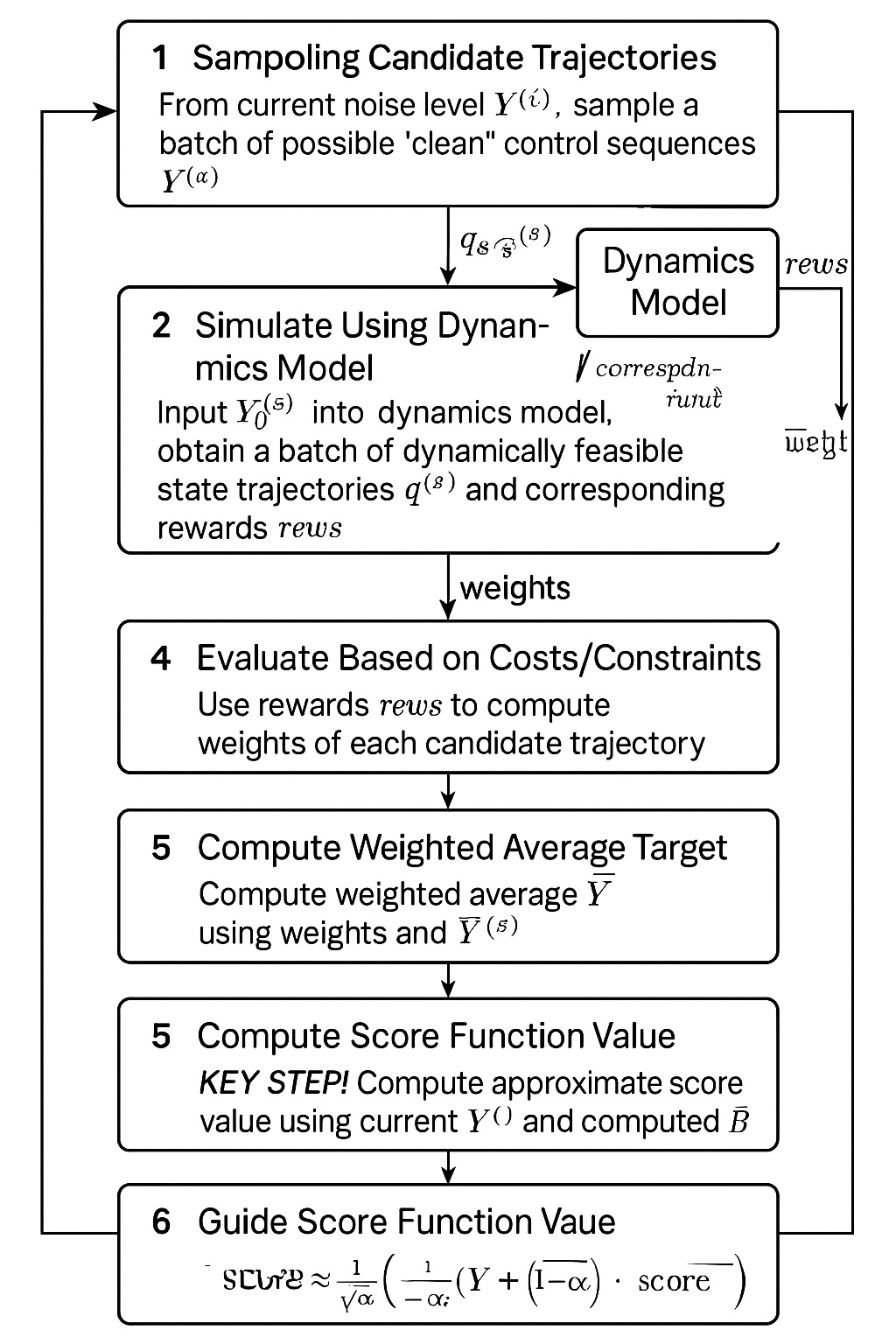
假设我们处于反向去噪的第 i 步,手头有噪声样本 Y(i):
采样候选轨迹:
- 从当前噪声水平
Y(i)出发,采样一批可能的“干净”控制序列Y0s
- 从当前噪声水平
使用动力学模型模拟:
- 将这些
Y0s输入动力学模型,得到一批动态可行的状态轨迹qs和对应的奖励rews。**(动力学模型信息在此注入)
- 将这些
根据成本/约束评估:
- 根据模拟得到的奖励
rews(它反映了成本函数和隐式约束)计算每个候选轨迹的权重weights。(成本/约束信息在此注入) - 权重反映了该轨迹的“好坏程度”(低成本、满足约束则权重高)。
- 根据模拟得到的奖励
计算加权平均目标:
- 使用
weights对原始采样的Y0s进行加权平均,得到一个综合了所有评估信息的“期望目标”控制序列Ybar Ybar = Σ(Y0s * weights) / Σ(weights)Ybar是一个蕴含了模型和任务信息的期望目标。
- 使用
计算评分函数值 (
score function):- 【关键步骤!】
- 将当前的
Yi和刚算出的Ybar代入一个标准的扩散理论公式: score ≈ (1 / (1 - ̄αᵢ)) * (-Yi + √ ̄αᵢ * Ybar)- 得到当前步骤评分函数的近似值
score。
指导扩散生成:
- 使用计算出的
score值,通过扩散模型的反向更新公式得到上一步的样本Yim1。 Yim1 = (1 / √αᵢ) * (Yi + (1 - ̄αᵢ) * score)
- 使用计算出的
通过迭代执行这 6 步 (从 i=N 到 1),MBD 就能从噪声生成优化后的轨迹。
MBD 不是修改评分函数的定义,而是设计了一种基于模型模拟和评估的计算方法,在每个反向步骤中算出评分函数的值。动力学模型、成本和约束的信息是通过影响第 4 步中计算出的 Ybar,进而影响第 5 步中计算出的 score 值,最终通过标准的反向更新步骤(第 6 步)来指导生成过程。
MBD 的优势与特点
- 数据无关: 无需演示数据即可进行轨迹优化。
- 模型驱动: 直接利用动力学、成本、约束等先验知识。
- 性能强大: 在复杂任务上表现优异,计算效率高(相比 RL)。
- 灵活整合: 可选择性地与不完美数据结合,进行引导或正则化。
总结
MBD 巧妙地绕开了训练评分网络的需要,通过一个基于模型的实时计算过程来估算评分函数,从而直接利用动力学、成本和约束信息指导扩散模型生成优化的轨迹。它不是改变评分函数的定义,而是改变了获取评分函数值的方法。
参考
[1] Model-Based Diffusion for Trajectory Optimization. https://lecar-lab.github.io/mbd/