文本分类项目:基于LSTM的电影评论情感分析【PyTorch 实现教程】
基于深度学习的文本分类,Kaggle代码LSTM 实现详解。
1 | |
1 | |
1 | |
| PhraseId | SentenceId | Phrase | Sentiment | |
|---|---|---|---|---|
| 0 | 1 | 1 | A series of escapades demonstrating the adage ... | 1 |
| 1 | 2 | 1 | A series of escapades demonstrating the adage ... | 2 |
| 2 | 3 | 1 | A series | 2 |
| 3 | 4 | 1 | A | 2 |
| 4 | 5 | 1 | series | 2 |
1 | |
| PhraseId | SentenceId | Phrase | |
|---|---|---|---|
| 0 | 156061 | 8545 | An intermittently pleasing but mostly routine ... |
| 1 | 156062 | 8545 | An intermittently pleasing but mostly routine ... |
| 2 | 156063 | 8545 | An |
| 3 | 156064 | 8545 | intermittently pleasing but mostly routine effort |
| 4 | 156065 | 8545 | intermittently pleasing but mostly routine |
1 | |
Construct Corpus...
100%|██████████| 156060/156060 [00:01<00:00, 106095.64it/s]
Convert Corpus to Integers
Convert Phrase to Integers
100%|██████████| 156060/156060 [00:01<00:00, 128755.83it/s]
代码详解
整体解释:
这段代码定义了一个名为Corpus_Extr的函数,用于从数据框df中构建语料库,并将语料库中的单词及短语转换为整数表示。下面是对函数中各步骤的详细解释:
构建语料库:
- 首先打印出
'Construct Corpus...'提示开始构建语料库。 - 通过迭代数据框
df中的每一行来构建一个单词列表corpus。对于df中的每个”Phrase”项,都将其转换为小写并分割成单词,然后加入到corpus列表中。
- 首先打印出
统计词频:
- 使用
np.hstack将corpus中的所有单词列表连接成一个大的一维数组。 - 使用
Counter统计这个数组中每个单词的出现次数,即得到一个词频字典corpus。
- 使用
排序语料库:
- 使用
sorted函数对corpus按词频降序排序,生成新的列表corpus2。
- 使用
将语料库中的单词转换为整数:
- 打印出
'Convert Corpus to Integers'提示开始转换。 - 通过
enumerate函数为排序后的语料库corpus2中的每个单词分配一个独一无二的索引(整数类型),从1开始编号(因为1作为参数传递给了enumerate),创建一个vocab_to_int字典。 例如,A的索引为3,对应的编号为3,,series的索引为315,则编号为315。
- 打印出
将短语转换为整数序列:
- 打印出
'Convert Phrase to Integers'提示开始转换。 - 再次迭代数据框
df的每一行,并使用vocab_to_int字典将每个短语中的单词转换为其对应的整数(索引),生成phrase_to_int列表。这个列表包含了转换为整数序列的短语。例如,短语为A series,则转换为[3, 315]
- 打印出
返回结果:
- 函数返回三个对象:
corpus(词频字典),vocab_to_int(单词到整数的字典),和phrase_to_int(短语到整数序列的列表)。
- 函数返回三个对象:
在函数调用的最后一行,Corpus_Extr函数被用于数据框train,并且将返回的对象赋值给变量corpus,vocab_to_int,和phrase_to_int。
细节解释:
corpus = Counter(np.hstack(corpus))
np.hstack()函数用于将两个或多个数组连接成一个数组,这里将corpus列表中的所有单词连接成一个数组,然后使用Counter()函数计算每个单词的计数。
Counter()函数用于计算序列中元素的频率。它接受一个可迭代对象(如列表、元组等)作为参数,并返回一个字典,其中键是序列中的元素,值是对应的元素出现的次数。
例如,如果corpus列表中包含以下单词:
1 | |
则corpus列表中的单词计数将如下所示:
1 | |
其中,'apple'出现了3次,'banana'和'orange'各出现了2次。
vocab_to_int = {word: idx for idx,word in enumerate(corpus2,1)}
创建了一个字典vocab_to_int,用于将corpus2中的单词映射到整数索引。
{}:这是字典的创建方法,表示创建一个空字典。word: idx:这是字典的键值对,其中word是键,idx是值。for idx, word in enumerate(corpus2, 1):这是一个for循环,用于迭代corpus2中的元素。enumerate函数将corpus2中的每个元素与它的索引配对。idx是索引,word是corpus2中的元素。enumerate(corpus2, 1):enumerate函数用于返回一个枚举对象,它生成一个包含索引和值的元组。参数1指定开始索引的值,这里设置为1。word: idx for idx, word in enumerate(corpus2, 1):这是一个字典推导式,它使用enumerate函数生成的元组创建字典的键值对。
代码行vocab_to_int = {word: idx for idx,word in enumerate(corpus2,1)}将corpus2中的单词作为键,索引作为值,创建了一个映射字典vocab_to_int。索引的起始值为1。 这个字典可以在后续代码中用来将单词转换为整数索引。
1 | |
代码解释
整体解释:
这段代码定义了一个名为Pad_sequences的函数,其功能是将整数序列列表phrase_to_int填充(或截断)到一个统一的长度seq_length。让我们逐步了解这个函数的工作流程:
初始化填充序列的矩阵:
- 创建一个名为
pad_sequences的矩阵,其形状为(len(phrase_to_int), seq_length),即行数等于整数序列列表中短语的数量,列数等于指定的序列长度seq_length。 - 该矩阵被初始化为零,并且数据类型设为整数。
- 创建一个名为
填充或截断序列:
- 通过迭代
phrase_to_int中的每个整数序列,enumerate函数提供当前序列的索引idx和序列的内容row。 tqdm被用于包装迭代器,显示进度条,total参数设定为phrase_to_int的长度,确保进度条反映整体进度。- 对于每一行,将行索引
idx对应的pad_sequences的前n个元素设置为row的内容,其中n是row的长度或seq_length中较小的一个,这保证了不会超过指定的序列长度。 - 如果
row的长度小于seq_length,则保持剩余元素为0(即填充);如果row的长度大于seq_length,则row将被截断到seq_length。
- 通过迭代
返回填充后的矩阵:
- 函数最终返回
pad_sequences矩阵,其包含了填充(或截断)后的整数序列。
- 函数最终返回
例如,如果我们有以下整数序列列表[[1, 2, 3], [4, 5]]和序列长度seq_length = 5,使用Pad_sequences函数后,我们会得到一个矩阵:
1 | |
填充技术常用于自然语言处理中,尤其是在准备训练模型的数据时,因为模型通常需要固定长度的输入序列。填充是增加额外的“无意义”数据来达到这个长度,而截断是丢弲末尾的数据以缩短序列长度。
细节解释:
pad_sequences[idx, :len(row)] = np.array(row)[:seq_length]
这行代码是Pad_sequences函数中用来对单个短语的整数序列进行填充或截断的关键操作。让我们分解这个操作:
pad_sequences[idx, :len(row)]:pad_sequences是一个二维numpy数组,其大小为(len(phrase_to_int), seq_length),其中len(phrase_to_int)是短语的总数,seq_length是填充后序列的固定长度。idx是当前正在处理的短语的索引。:len(row)是一个切片操作,用来指定pad_sequences的第idx行的从第一个元素到len(row)个元素。这意味着只有当前短语长度内的部分将被新值替换,超出当前短语长度的部分(即填充部分)仍然保持初始化时的零值。- 当
len(row)< =seq_length时,pad_sequences[idx, :len(row)]表示pad_sequences前len(row)个值替换为row(短语的整数序列)。 - 当
len(row)>seq_length时,pad_sequences只能切片到seq_length的长度,即pad_sequences前seq_length个值替换为row(短语的整数序列)的前seq_length个值。
np.array(row)[:seq_length]:row表示当前短语的整数序列。np.array(row)将这个列表转换为numpy数组,以使用numpy的切片功能。[:seq_length]是一个切片操作,用来选取从开头到seq_length位置的元素。这里的作用是确保即使row的长度大于seq_length,也只选取前seq_length个元素进行操作。
综合来看,pad_sequences[idx, :len(row)] = np.array(row)[:seq_length]这行代码的作用是:
- 如果当前整数序列
row的长度小于或等于seq_length,那么row中的全部元素将被复制到pad_sequences的第idx行,且不会有任何改变(row长度小于seq_length时,剩余部分保持为零)。 - 如果当前整数序列
row的长度大于seq_length,那么row将被截断,只有前seq_length个元素被复制到pad_sequences的第idx行。
这种操作允许在不改变原有语料顺序的基础上,统一短语的长度,以便它们能被用于需要固定大小输入的机器学习模型中。
1 | |
100%|██████████| 156060/156060 [00:00<00:00, 586561.27it/s]
1 | |
| PhraseId | SentenceId | Phrase | Sentiment | |
|---|---|---|---|---|
| 146370 | 146371 | 7961 | Ever see one of those comedies that just seem ... | 1 |
| 109634 | 109635 | 5809 | The slapstick is labored , and the bigger setp... | 0 |
| 38716 | 38717 | 1845 | this turd | 0 |
| 155765 | 155766 | 8526 | The Santa Clause 2 is a barely adequate babysi... | 1 |
| 35762 | 35763 | 1687 | be able to look away for a second | 3 |
| 154282 | 154283 | 8431 | been lost in the translation this time | 1 |
| 28948 | 28949 | 1341 | is very , very far | 1 |
| 18779 | 18780 | 825 | averting | 2 |
| 75864 | 75865 | 3891 | I could not stand them | 0 |
| 14023 | 14024 | 603 | playful respite | 3 |
| 3146 | 3147 | 118 | sumptuous | 3 |
| 21437 | 21438 | 959 | real star | 3 |
| 100844 | 100845 | 5296 | about black urban professionals | 2 |
| 15019 | 15020 | 646 | benevolent deception , which , while it may no... | 3 |
| 127717 | 127718 | 6869 | 's also a -- dare I say it twice -- delightful... | 4 |
| 149868 | 149869 | 8160 | a good ear for dialogue , | 3 |
| 51768 | 51769 | 2553 | accessible and | 3 |
| 132644 | 132645 | 7152 | a waste of De Niro , McDormand and the other g... | 1 |
| 69389 | 69390 | 3527 | solid sci-fi thriller | 3 |
| 66970 | 66971 | 3399 | Close Encounters | 2 |
| 106267 | 106268 | 5610 | does a flip-flop | 2 |
| 74661 | 74662 | 3828 | made about an otherwise appalling , and downri... | 2 |
| 136015 | 136016 | 7348 | at its most | 2 |
| 92024 | 92025 | 4788 | given up on in favor of sentimental war movies... | 2 |
| 148394 | 148395 | 8074 | guns , drugs , avarice and damaged dreams | 2 |
| 97725 | 97726 | 5116 | baseball-playing | 2 |
| 43334 | 43335 | 2094 | and , through it all , human | 3 |
| 99334 | 99335 | 5209 | represents an engaging and intimate first feat... | 3 |
| 74235 | 74236 | 3802 | wise men | 3 |
| 19568 | 19569 | 859 | bear suits | 2 |
| 85740 | 85741 | 4435 | a bore | 1 |
| 78392 | 78393 | 4032 | 're most likely to find on the next inevitable... | 1 |
| 64844 | 64845 | 3283 | a bumbling American in Europe | 2 |
| 65549 | 65550 | 3320 | who face arrest 15 years after their crime | 2 |
| 3660 | 3661 | 138 | does n't end up having much that is fresh to s... | 1 |
| 20350 | 20351 | 909 | it is all awkward , static , and lifeless rumb... | 2 |
| 81036 | 81037 | 4176 | of hell so shattering it | 1 |
| 87753 | 87754 | 4556 | real visual charge | 3 |
| 40372 | 40373 | 1932 | speculative effort | 3 |
| 87707 | 87708 | 4554 | compensate for them | 2 |
| 45668 | 45669 | 2219 | me want to bolt the theater in the first 10 mi... | 0 |
| 118321 | 118322 | 6321 | tweaked up | 2 |
| 31405 | 31406 | 1468 | just zings along with vibrance and warmth . | 4 |
| 49093 | 49094 | 2398 | romantic thriller | 3 |
| 32154 | 32155 | 1506 | und drung , but explains its characters ' deci... | 1 |
| 20466 | 20467 | 913 | the second half | 2 |
| 56965 | 56966 | 2866 | one big laugh , three or four mild giggles , and | 3 |
| 60104 | 60105 | 3032 | Galinsky | 2 |
| 109183 | 109184 | 5781 | true emotions | 3 |
| 73647 | 73648 | 3766 | is how so many talented people were convinced ... | 0 |
1 | |
1 | |
代码解释
这段代码定义了一个名为SentimentRNN的类,它是一个继承自nn.Module的PyTorch神经网络模型,用于情感分析。下面是详细解释每个部分:
类初始化方法 (__init__):
self.output_size: 输出层的大小。self.n_layers: LSTM层的数量。self.hidden_dim: LSTM层中隐藏状态的特征维度。self.embedding: 嵌入层,使用nn.Embedding根据语料库大小和词嵌入维度embedd_dim创建了一个查找表,用于将单词整数映射转成嵌入向量。self.lstm: LSTM层,定义了LSTM网络的结构,包括输入数据的维度embedd_dim、隐藏层维度hidden_dim、层数n_layers、以及dropout比率为0.5,batch_first=True指明输入数据的第一个维度是批次大小。self.dropout: 丢弃层,使用nn.Dropout定义丢弃率为0.3以减少过拟合。self.fc: 全连接层,使用nn.Linear将LSTM的输出映射到输出层的大小output_size。self.act: 激活层,使用nn.Sigmoid函数,该函数的输出通常用于二分类情感分析(输出一个概率值表示正面情感的概率)。
前向传播方法 (forward):
batch_size: 通过获取输入x的第一个维度大小来确定批次大小。embeds: 使用嵌入层将输入的单词整数序列转换为嵌入向量。lstm_out,hidden: LSTM层的输出和隐藏状态。lstm_out = lstm_out.contiguous().view(-1,self.hidden_dim): 调整LSTM层输出的形状以匹配全连接层的输入要求。self.dropout(lstm_out): 应用丢弃层。self.fc(out): 将丢弃层的输出通过全连接层。self.act(out): 使用Sigmoid激活函数。
接着将处理过的输出调整回批次格式,并通过out[:,-5:]得到每个序列的最后五个时间步(短语)的结果。这假定情感的输出可能取决于序列的最后几个单词。
初始化隐藏状态方法 (init_hidden):
- 用于初始化一个包含两个全零张量的隐藏状态元组。(一个用于LSTM的隐藏状态,另一个用于LSTM的细胞状态)。
batch_size: 批次大小,决定了隐藏状态的第二维的大小。weight.new: 创建一个与模型参数同类型的张量,self.parameters()是一个迭代器,包含模型所有参数。zero_(): 将张量内的所有元素置为0。
总体来说,这个SentimentRNN是一个用于情感分析的循环神经网络,它会输出每个输入序列的情感倾向,这是通过查看序列最后五个元素的输出来判断的。这个网络在初始化时需要定义一系列的参数,并在之后可以接收输入数据和相应的隐藏状态进行前向传播以及在训练前初始化隐藏状态。
1 | |
1 | |
SentimentRNN(
(embedding): Embedding(16531, 400)
(lstm): LSTM(400, 256, num_layers=2, batch_first=True, dropout=0.5)
(dropout): Dropout(p=0.3, inplace=False)
(fc): Linear(in_features=256, out_features=5, bias=True)
(act): Sigmoid()
)
1 | |
1 | |
Epoch: 1/200... Step: 1... Loss: 1.412927...
acc:0.46875
Epoch: 1/200... Step: 11... Loss: 1.417399...
acc:0.47159090638160706
Epoch: 1/200... Step: 21... Loss: 1.408894...
acc:0.480654776096344
Epoch: 1/200... Step: 31... Loss: 1.404616...
acc:0.4868951737880707
Epoch: 2/200... Step: 33... Loss: 1.388400...
acc:0.5
Epoch: 2/200... Step: 43... Loss: 1.389541...
acc:0.5
Epoch: 2/200... Step: 53... Loss: 1.389531...
acc:0.5104166865348816
代码解释
这段代码是一个典型的深度学习训练循环,用于训练一个名为net的神经网络。代码的主要组成部分是设置训练参数、定义损失函数、配置优化器以及执行训练循环。这里是每个部分的详细解释:
初始化训练参数:
net.train():确保处于训练模式,特别是对于包含dropout或批归一化层的网络。clip=5:设置梯度裁剪的最大阈值,防止梯度爆炸问题。epochs = 200:将网络训练200个时代(epochs)。counter = 0:用以计数训练步骤总数。print_every = 100:每训练100个batch,打印一次训练信息。lr=0.01:设置优化器的学习率为0.01。
定义自定义损失函数:
在上述代码中,自定义的损失函数
criterion用于计算分类任务中的交叉熵损失。这个函数接受两个参数:input和target,以及一个可选的参数size_average,详细解释如下:(1) 参数:
input:模型的原始输出(logits),在多分类问题中通常是一个二维张量,形状为(batch_size, num_classes),表示批量数据的类别未归一化的预测分数。target:实际标签的one-hot表示,形状与input相同,每一行对应于一个样本的类别标签的one-hot编码。size_average:布尔值,决定最终损失是否要在样本上取平均。默认值True表示计算损失的平均值,而False表示损失的总和。
(2) 损失计算流程:
1. `F.softmax(input, dim=1)`: 对`input`应用Softmax函数,以每个样本的预测分数转换成概率分布。Softmax作用在第一个维度上(`dim=1`),即将每一个样本的logits归一化成概率值。 2. `+ 1e-10`: 在应用对数函数前,加上一个小的常数`1e-10`,防止数值不稳定问题,尤其是防止当概率值为零时对数无法计算的情况。 3. `torch.log(...)`: 对Softmax的结果取对数。因为交叉熵损失涉及到概率的对数,所以需要这一步。 4. `-(target * ...)`: 将目标one-hot向量与对数概率相乘。在one-hot编码中,正确标签的位置为1,其余位置为0,因此这一操作将选出每个样本正确类别的对数概率。 5. `.sum(1)`: 对每个样本的结果按类别求和,由于正确标签的位置为1其他为0,因此每个样本只计算了正确类别的负对数似然。 6. `if size_average ... else ...`: 根据`size_average`参数的值,决定是计算损失的平均值(`.mean()`)还是总和(`.sum()`)。 7. `return l`: 返回计算后的损失值。配置优化器:
optimizer:一个使用Adam优化算法和指定学习率来更新net参数的优化器。
训练过程:
- 初始化和构建训练数据:
a = np.random.choice(len(train)-1, 1000): 从train数据集中随机选择1000个样本(不包括最后一个)。len(train)-1确保在选择时不会超出索引范围。train_set = PhraseDataset(train.loc[train.index.isin(np.sort(a))], pad_sequences[a]): 使用选中的样本索引来创建train_set,一个PyTorch数据集。PhraseDataset是一个自定义数据集类,用于存储训练数据和对应的序列化表示(pad_sequences[a])。train_loader = DataLoader(train_set, batch_size=32, shuffle=True): 利用DataLoader将train_set封装成一个可迭代的数据加载器,每次迭代返回一批数据。参数batch_size=32指明每批次包含32个样本,shuffle=True表示在每个epoch开始时,数据将被打乱。
- 训练循环:
对于每一个epoch(一个epoch表示遍历一次完整的数据集):
h = net.init_hidden(32): 初始化网络的隐藏状态。这对于训练RNNs(递归神经网络)或LSTMs(长短期记忆网络)是必要的。running_loss = 0.0和running_acc = 0.0: 初始化变量用于累计一个epoch中所有批次的损失和准确率。
接下来,对于每一个批次:
gc.collect(): Python的垃圾收集器,用来尝试释放内存中未使用的对象。
每个batch循环开始:
h = tuple([each.data for each in h]): 分离隐藏状态,以免在整个训练历史中进行反向传播。optimizer.zero_grad(): 清零之前的梯度,否则梯度将会累加到已有的梯度上。if inputs.shape[0] != batch_size: break: 如果当前批次的大小不等于预设的batch_size,则跳过该批次。output, h = net(inputs, h): 通过模型进行前向传播,得到预测输出和新的隐藏状态。labels = torch.nn.functional.one_hot(labels, num_classes=5): 将标签转换为one-hot编码,总共有5个类别。loss = criterion(output, labels): 计算模型输出和实际标签之间的损失。loss.backward(): 进行反向传播,计算损失对模型参数的梯度。running_loss += loss.cpu().detach().numpy(): 将当前batch的损失累加到总损失上。running_acc += (output.argmax(dim=1) == labels.argmax(dim=1)).float().mean(): 计算并累加当前batch的准确率。nn.utils.clip_grad_norm_(net.parameters(), clip): 对梯度进行裁剪,以防止梯度爆炸。optimizer.step(): 更新网络参数。
- 打印和记录训练进度:
if idx % print_every == 0: 满足条件时,即经过print_every设置的数目的批次后,打印当前训练的状态。打印包含当前epoch、步数、损失的字符串。
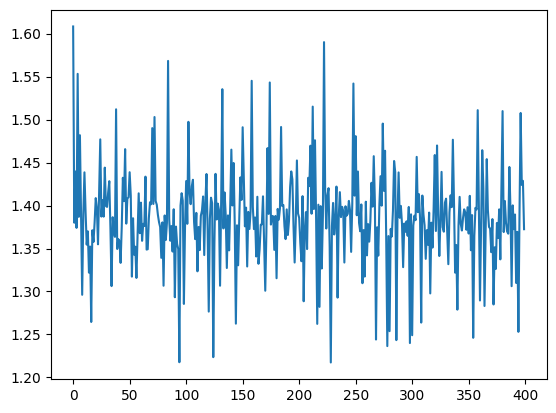
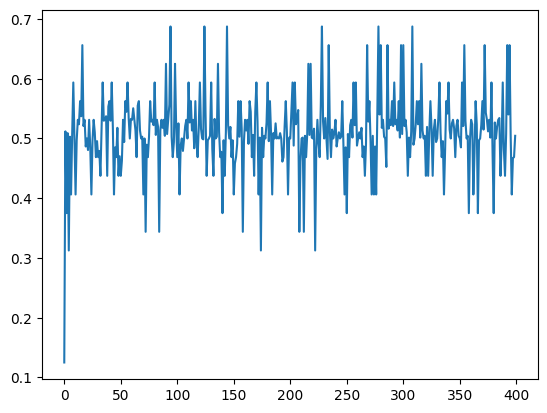
losses.append(float(running_loss/(idx+1)))和accs.append(running_acc/(idx+1)): 将平均损失和平均准确率记录到列表中,用于之后分析模型训练过程的性能。
1 | |