机器学习03-模型评估
模型选择
如何评估学习算法,自动选择模型?
模型选择&交叉验证测试集的训练方法
因为d也是一个需要学习的参数,不断选择d的过程本质上和学习模型内参数w,b是一致的,而超参数d本就是靠在test集上测试找到的,而test集在这里就成为参数d的“训练集”,所以这样得出的d是过拟合的
简而言之 Training set 用来 选 w&b, cross validation用来选 d , Test set 用来评估 模型 最终的 泛化误差 - 就是这个模型好不好
训练集:得到模型,得到每个模型的w,b
验证集:挑选模型,挑选某一个模型
测试集:评估挑选的模型的泛化能力
只有在你想出一个模型作为你的最终模型之后,才可以在测试集上对其进行评估,并且因为你没有使用测试集做出任何决定,这可以确保你的测试集是公平的而不是过度的对您的模型对新数据的泛化能力的乐观估计
选择几个模型进行训练,然后用交叉验证集对几个模型进行损失值评估,以此选出最好的模型,再通过测试集新数据评估该模型泛化误差
偏差与方差
高偏差(欠拟合)
高方差(过拟合)
多项式最高次数与代价函数值图: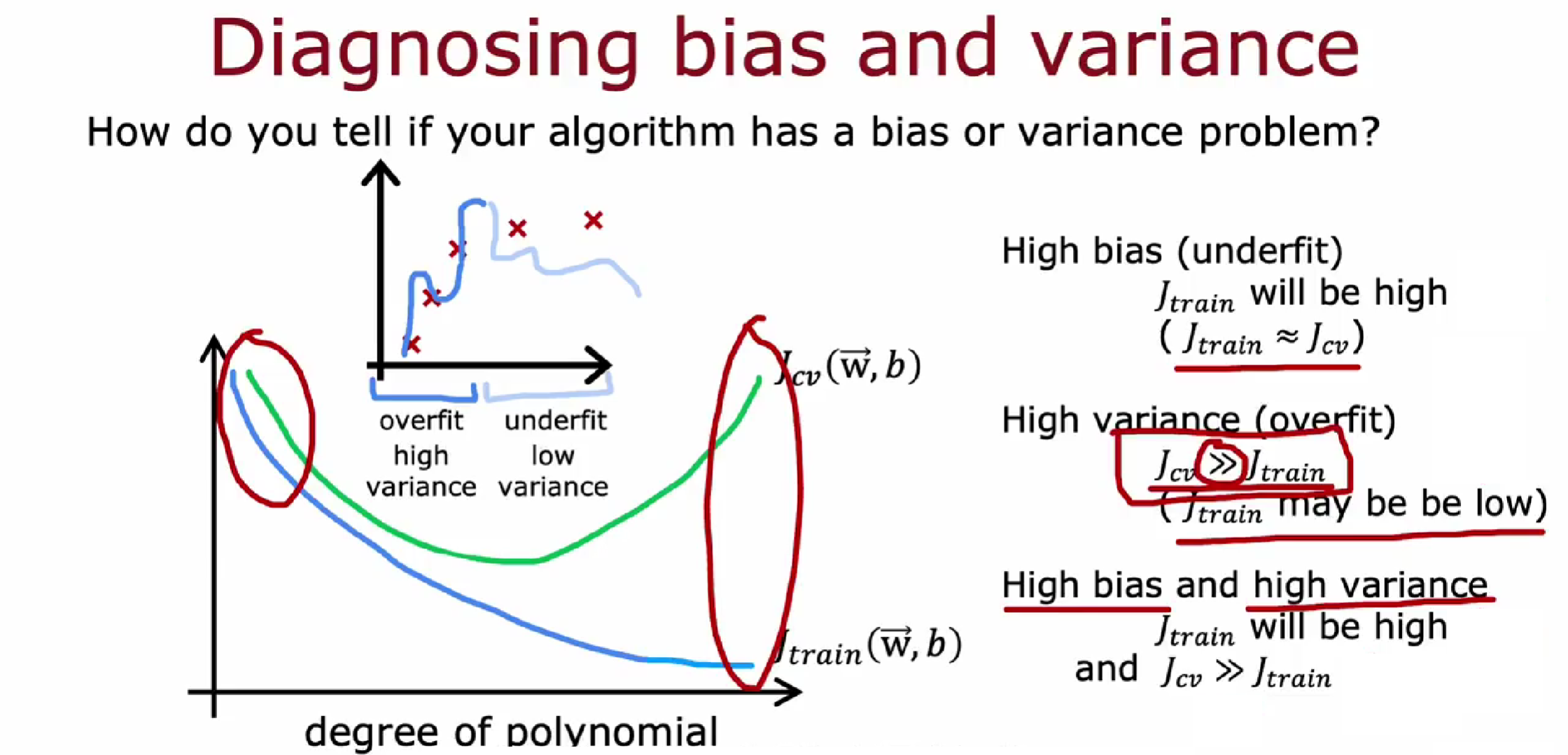
多项式次数低,欠拟合,训练集成本函数值($J_{train}$)高,交叉验证集成本函数值($J_{cv}$)高。
多项式次数高,过拟合,$J_{train}$ 低,$J_{cv}$ 高。
一般在神经网路中才同时具有高偏差和高方差。
高偏差意味着在训练集上做的不好。高方差意味着在训练集和交叉验证集都不好。
正则化如何影响方差和偏差
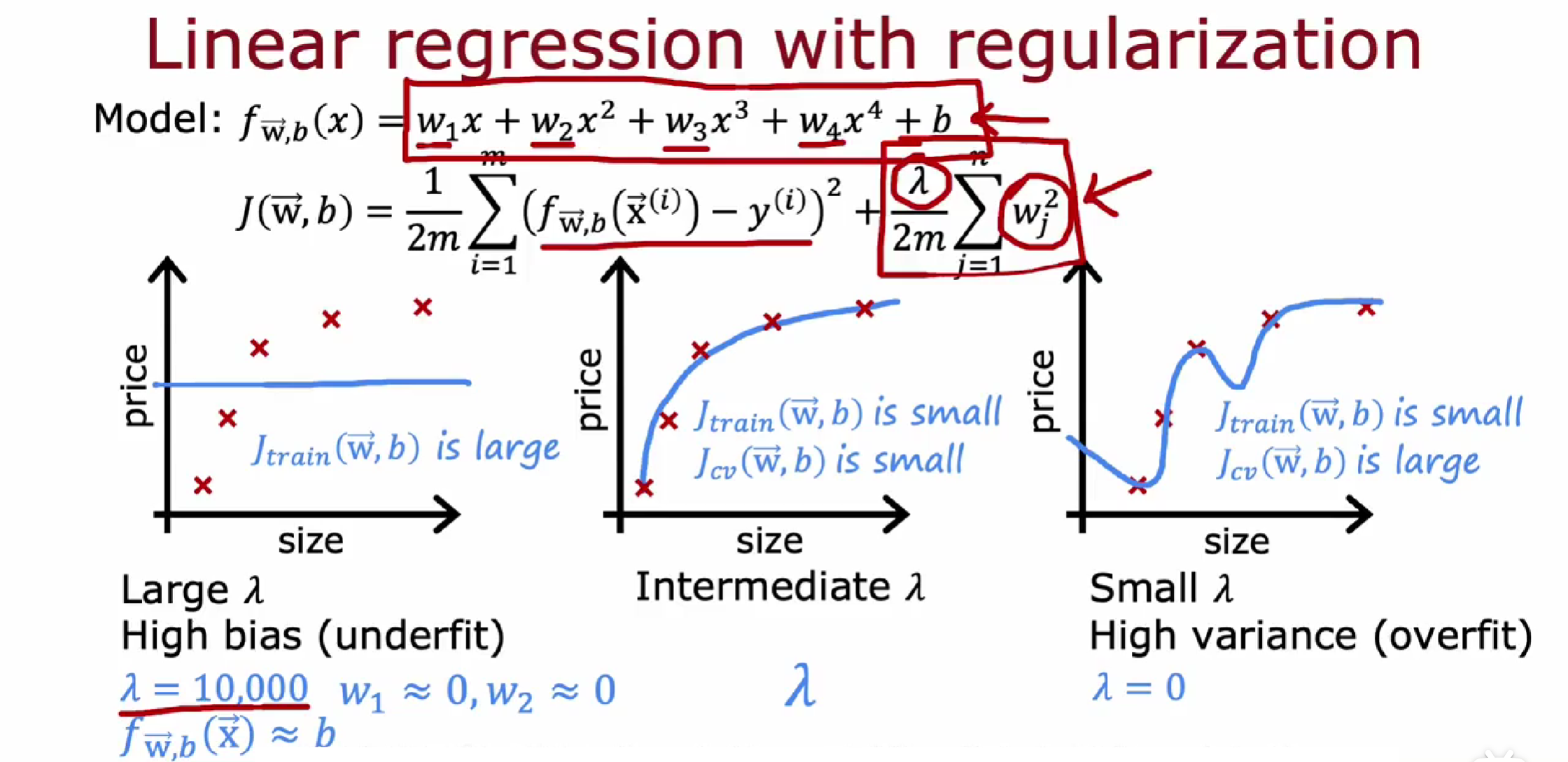
正则化中 $\lambda$ 评估
$\lambda$ 与代价函数值图: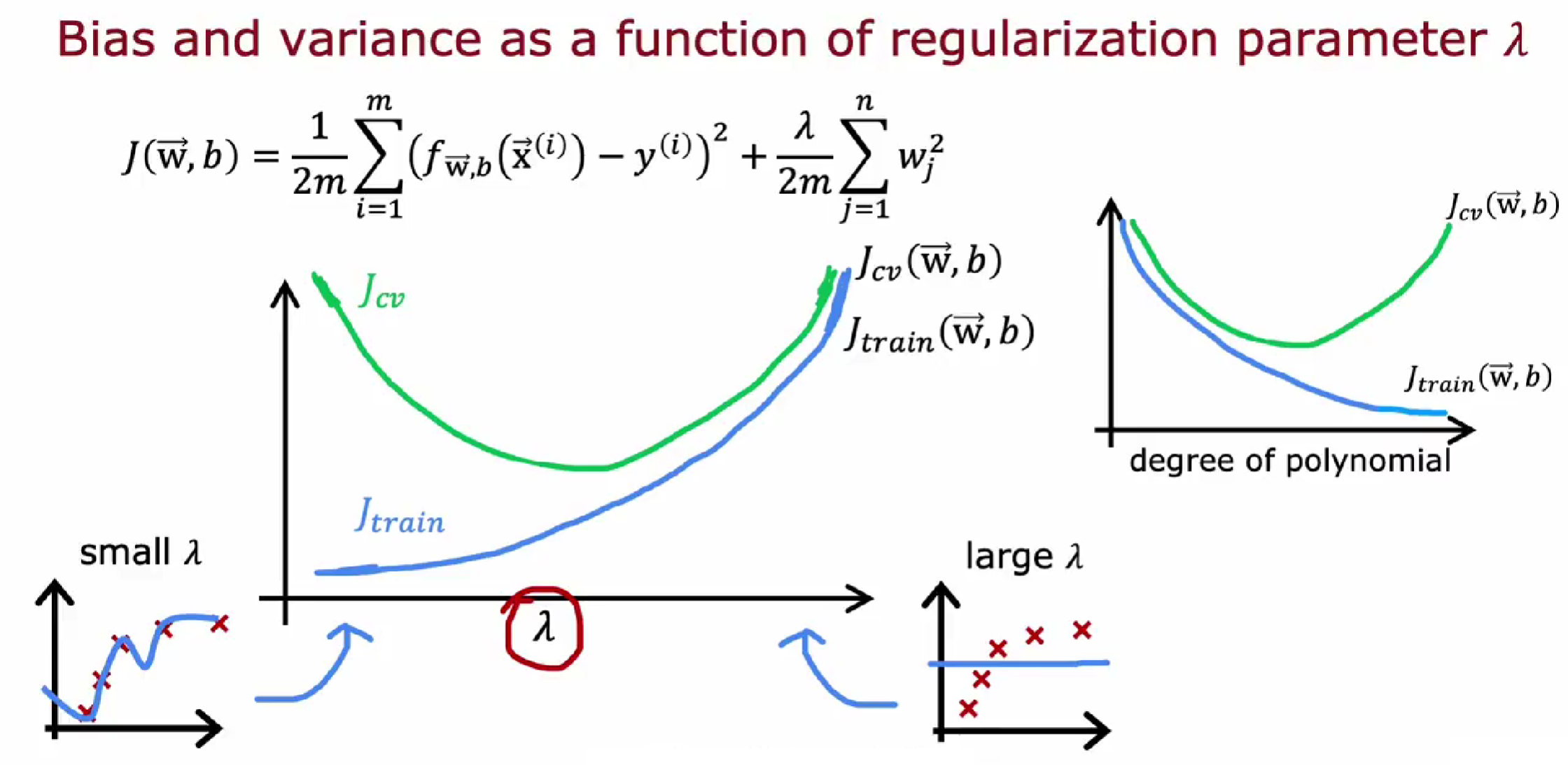
$\lambda$ 小,过拟合,$J_{train}$ 低,$J_{cv}$ 高。
$\lambda$ 大,欠拟合,$J_{train}$ 高,$J_{cv}$ 高。
性能评估的基准

评估基准:你希望算法能达到的性能是多少
- 人类水平的表现
- 竞争对手的算法,其他人以前已经实现的算法
- 以往的经验
是否具有高方差/偏差

相互比较
高偏差的学习曲线
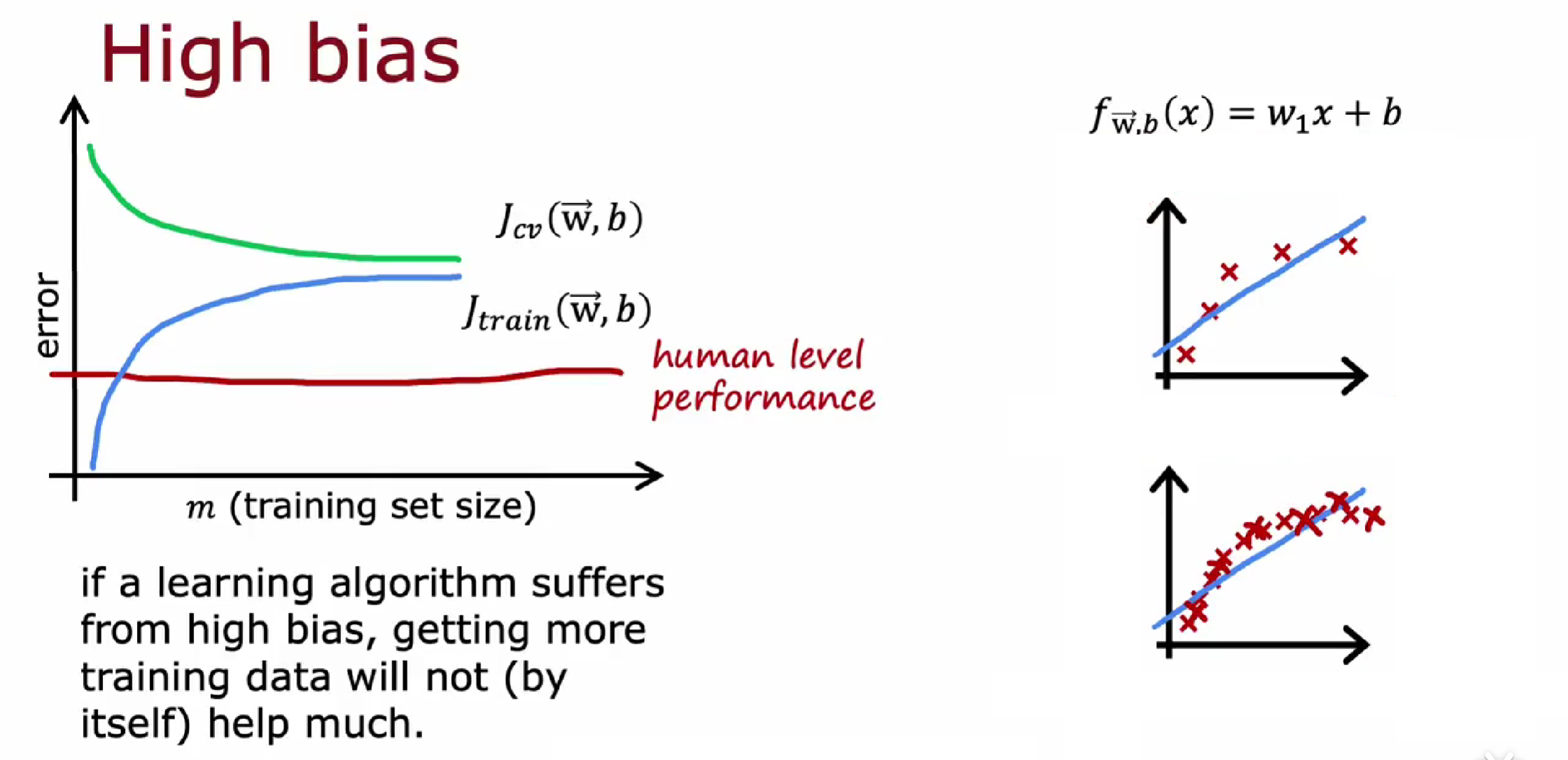
具有高偏差欠拟合的模型,加训练数据量没法改善,从模型选择就有问题;
欠拟合对新数据不敏感
高方差的学习曲线
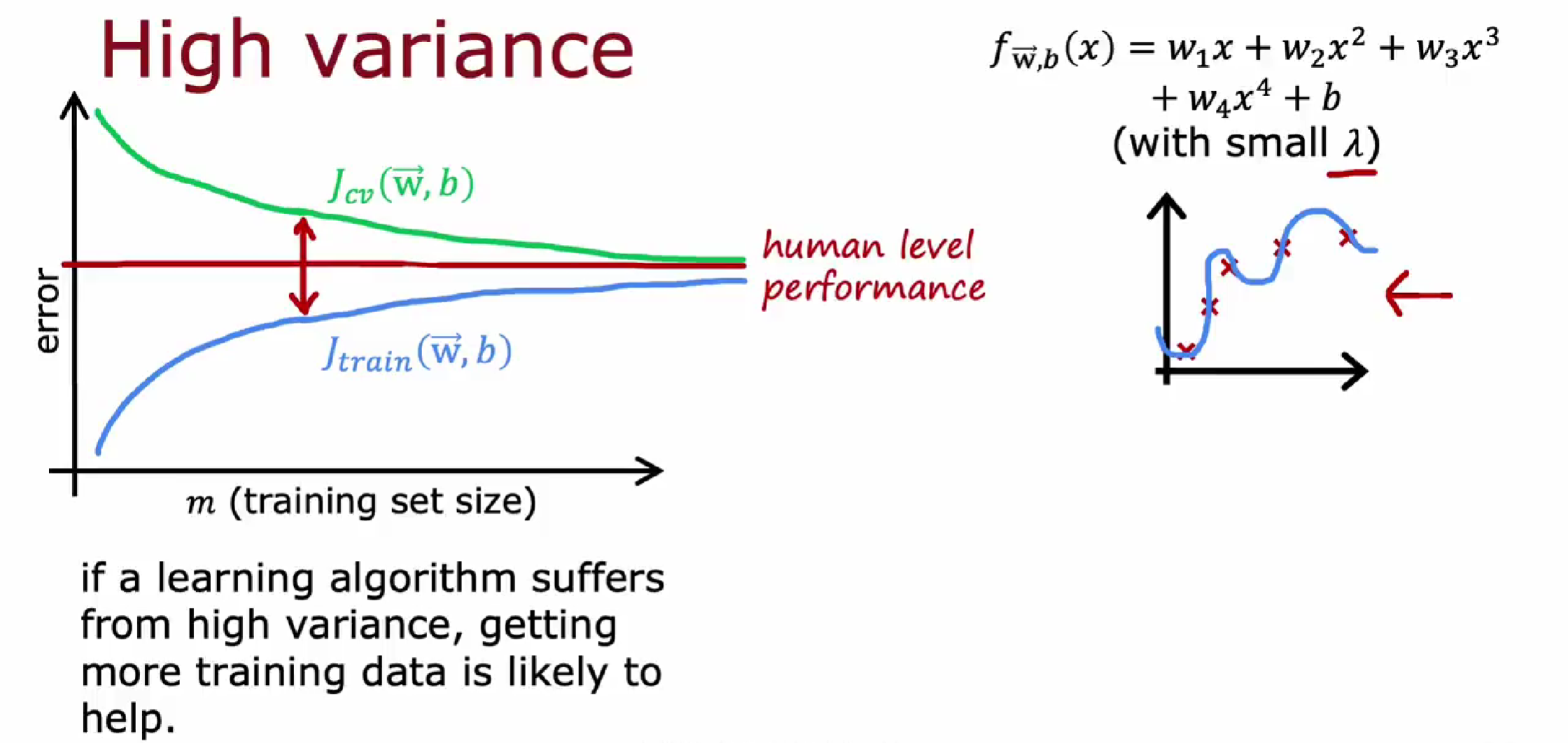
高方差过拟合加训练数据量可以改善;
过拟合对新数据特别敏感。
缺点是,使用训练集的不同大小的子集来训练这么多不同的模型在计算上非常昂贵,在实践中,并没有这样做。虽然如此,在脑海中形成训练集的视觉图像,有时可帮助思考学习算法在做什么,是否具有高偏差或高方差
调试学习算法

高方差:增加训练数据,简化模型(减少特征、增加$\lambda$)
高偏差:强化模型(增加特征、增加多项式、降低$\lambda$)
误差分析
算法错误分类了100个样本,我们手动分析这一百个样本,并试图深入了解算法出错的地方,将它们分组为共同的主题或共同的属性或共同的特征。
分析发现:
药品垃圾邮件21件
故意拼写错误3件
邮件路由错误7件
钓鱼邮件18件
图片5件
那我们将重心放在识别药品垃圾邮件和钓鱼邮件,而不是放在识别拼写错误这种净影响实际上非常小的问题上。
例如对于药品垃圾邮件,可以收集更多的关于药物垃圾邮件数据,而不是收集更多的所有数据,以便学习算法可以更好地识别这些药物垃圾邮件。
但是现在错误分析的一个局限性是它更容易解决人类擅长的问题。比如人们可以直接的分辨出是否为垃圾邮件,对于连人类都不擅长的任务,错误分析可能会更难一些,例如,如果试图预测人们会点击网站上的哪些链接。对于这种主观性较大的事件,可能无法预测人会点击什么。
添加有帮助的数据
采用现有的训练示例并对其进行修改、扭曲以创建另一个训练示例。
例如,计算机视觉常用合成数据进行增加训练样本。
有时花更多时间采用以数据为中心的方法会更有成效,在这种方法中,专注于设计算法使用的数据,数据可以来源于收集、数据增强、数据合成。
可以用迁移学习的方法获取数据,关键在于从几乎不相关的任务中获取数据。
迁移学习
迁移学习可以使用其他任务中的数据应用于程序,核心思想是从一个任务学到的知识或模型应用于另一个相关任务上。通过迁移学习,可以在目标任务上利用源任务的经验和模型参数,从而加快目标任务的训练速度、提高预测性能。
迁移学习的基本假设是:不同的任务之间存在某种共享的特征表示或知识,这些特征和知识对于解决其他任务也是有用的。通过迁移学习,可以利用源任务的经验来帮助目标任务的学习,尤其在目标任务的数据较少或难以获取的情况下,迁移学习可以发挥重要作用。
假设要识别从0-9的手写识别,但是没有这么多用于训练的数据。
可以这样做,
假设您找到了一个非常大的数据集,其中包含一百万张猫、狗、汽车等一千个类别的图片,然后,您可以用这一百万张图片训练一个识别个个类别的神经网络,即训练算法将一百万张图像X作为输入,将1,000个不同的类别作为输出。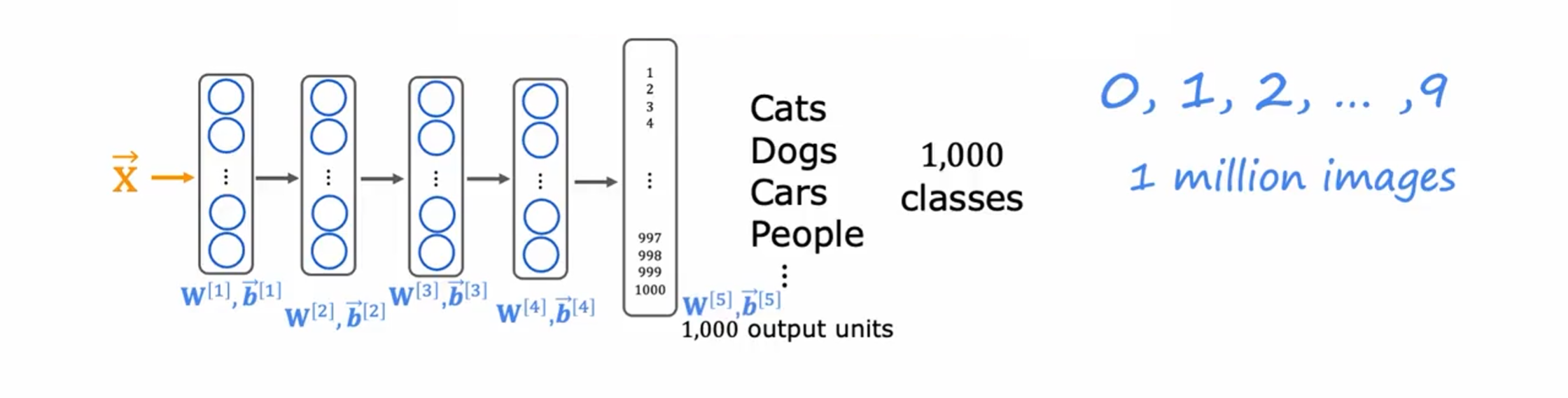
这个神经网路共五层,四个隐藏层和一个输出层。各层的参数分别为$\mathbf{W}^{[1]},\vec{\boldsymbol{b}}^{[1]}$、$\mathbf{W}^{[2]},\vec{\boldsymbol{b}}^{[2]}$、$\mathbf{W}^{[3]},\vec{\boldsymbol{b}}^{[3]}$、$\mathbf{W}^{[4]},\vec{\boldsymbol{b}}^{[4]}$、$\mathbf{W}^{[5]},\vec{\boldsymbol{b}}^{[5]}$
要应用迁移学习,您要做的是复制此神经网络,在其中插入参数$\mathbf{W}^{[1]},\vec{\boldsymbol{b}}^{[1]}$、$\mathbf{W}^{[2]},\vec{\boldsymbol{b}}^{[2]}$、$\mathbf{W}^{[3]},\vec{\boldsymbol{b}}^{[3]}$、$\mathbf{W}^{[4]},\vec{\boldsymbol{b}}^{[4]}$
但对于最后一层输出层,用0-9代替原来的一千个分类,然后用优化 算法,例如梯度下降或Adma算法仅更新 $\mathbf{W}^{[5]},\vec{\boldsymbol{b}}^{[5]}$ ;对于$\mathbf{W}^{[1]},\vec{\boldsymbol{b}}^{[1]}$-$\mathbf{W}^{[4]},\vec{\boldsymbol{b}}^{[4]}$ 用原来的值 不更新。
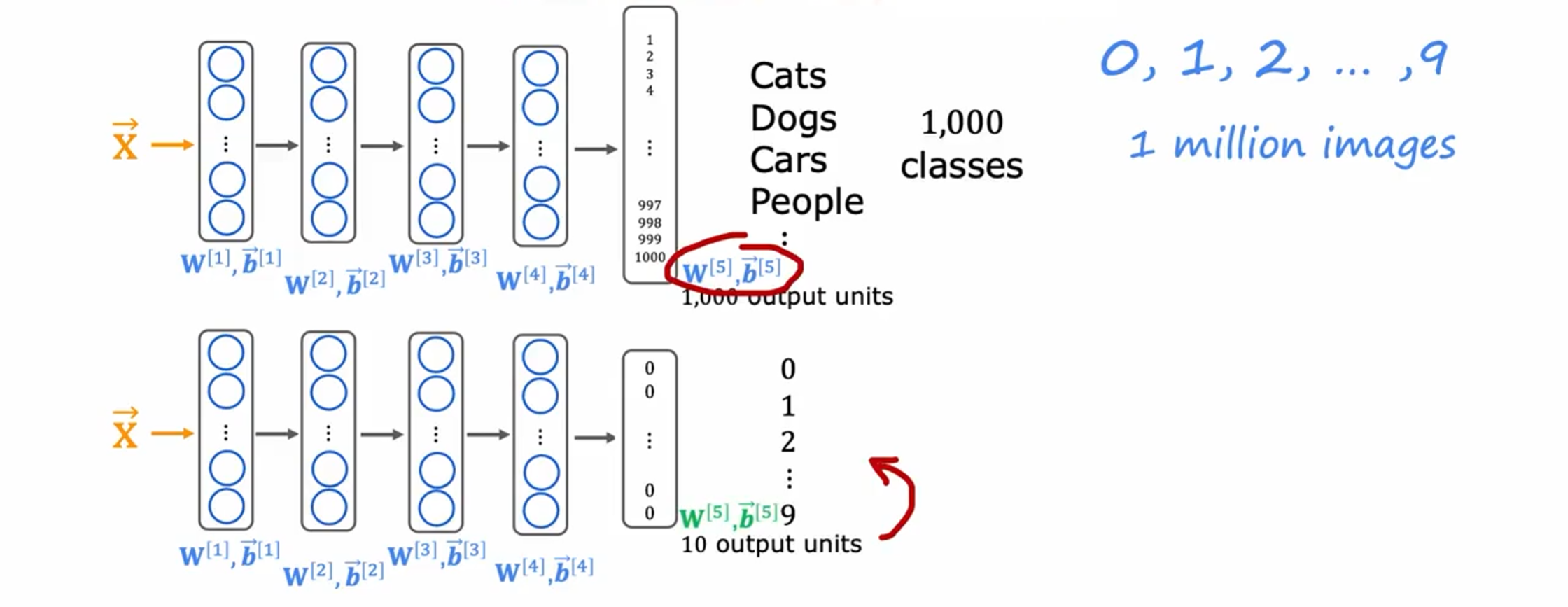
另一种策略是,更新所有的参数,但是$\mathbf{W}^{[1]},\vec{\boldsymbol{b}}^{[1]}$、$\mathbf{W}^{[2]},\vec{\boldsymbol{b}}^{[2]}$、$\mathbf{W}^{[3]},\vec{\boldsymbol{b}}^{[3]}$、$\mathbf{W}^{[4]},\vec{\boldsymbol{b}}^{[4]}$ 使用上面训练过的值作为初始值,在此基础上进行更新。
如果有一个非常小的训练集,前一种策略较好,如果训练集稍微大一点,后一种策略较好。
迁移学习的两个步骤,首先在大型数据集上进行训练,即预训练;然后在较小的数据集上进一步调整参数,即微调。
我的理解:
预训练是用预训练的数据集找出一个大致的工作模板,第一步该干什么,第二步该干什么什么,最后得出结论。
微调是在已有的工作模板上直接按部就班,但是需要进行一些改动、优化,使之变得符合本项目的工作流程。
GPT:
预训练的目标是通过大规模数据集,使模型学习到一些通用的特征表示或知识。这个过程可以被看作是为模型提供一个“大致的工作模板”,其中包含了一些普遍适用的信息。预训练可以使用无监督学习方法,如自编码器或生成对抗网络,也可以使用有监督学习方法。预训练后的模型通常具有更好的初始特征表示能力。
微调则是在预训练模型的基础上,通过在目标领域的较小数据集上进行进一步训练来调整模型参数。微调过程中,可以根据具体任务的需求进行一些改动、优化或修正,以使模型更符合目标任务的工作流程。微调的目的是将预训练模型适应特定任务的特征和表现能力,提高模型在目标领域上的性能。
总结来说,预训练提供了一个初始的模板或特征表示,微调则是在此基础上进行调整和优化,以适应具体的任务需求和数据分布。这样的迁移学习方法可以减少对大量标注数据的依赖,提高模型的泛化性能。
倾斜数据集的误差指标
如果正例与负例比例偏差很大,那么像准确度这种错误指标效果不佳。
假设正在训练一个二分类模型,检测患者是否患罕见疾病,在人群中只有0.5%发病率。
对于这种倾斜数据集的衡量常用准确率(Precisionn)和召回率(Recall)
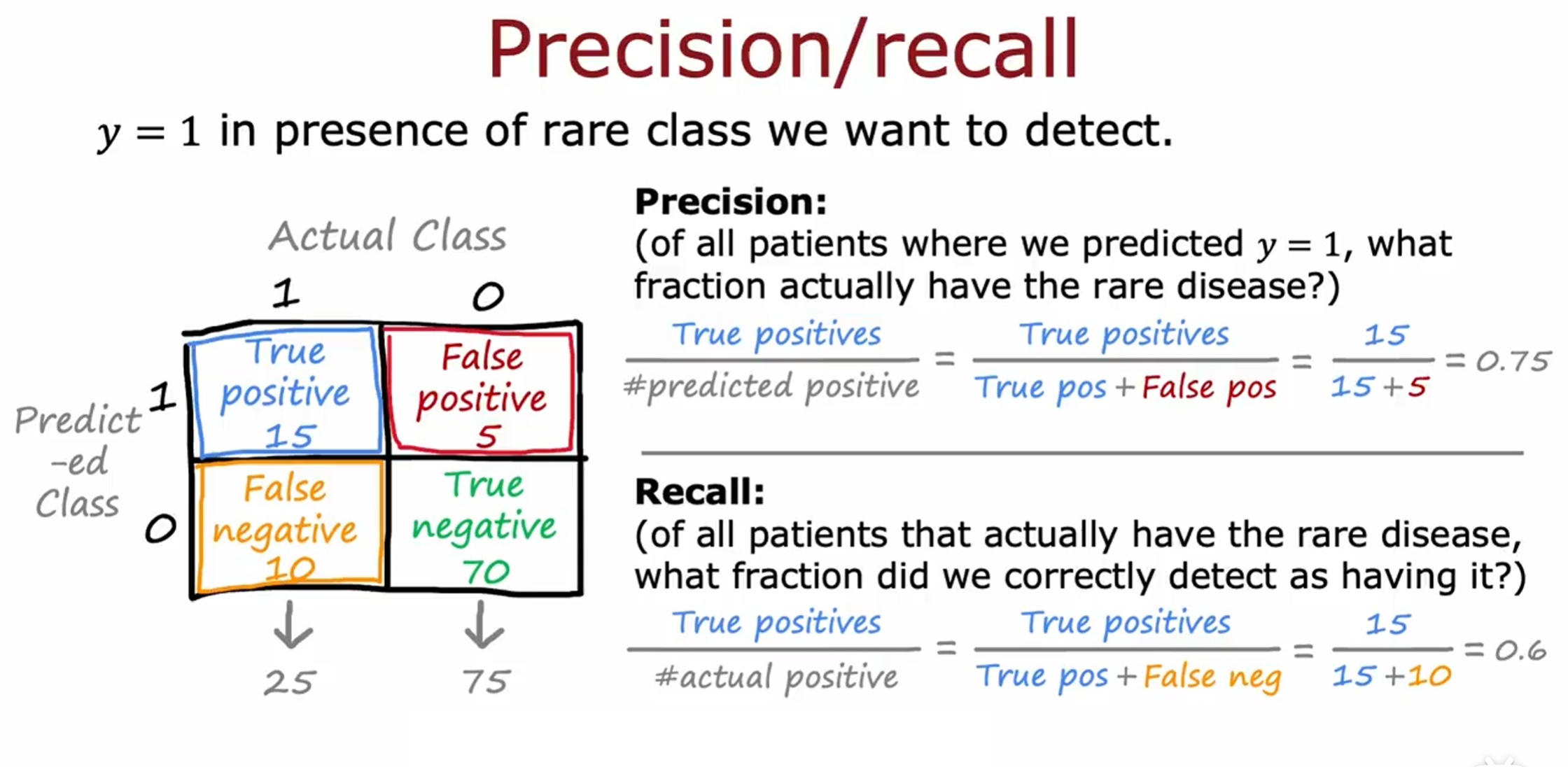
高精度意味着如果患者被诊断患有这种罕见疾病,那么该患者可能确实患有这种疾病,并且这是一个准确的诊断。
高召回率意味着如果有患者患有这种罕见疾病,算法可能会正确识别出他们确实患有这种疾病。
预测的准确性和漏判的概率
Precision很高:说话靠谱;Recall很高:遗漏率很低。
当两者都较高时模型才有较好的效果。
因此,当有偏斜类或想要检测稀有类时,精确率和召回率可以判断算法是否做出了良好的预测或有用的预测。
精确率与召回率的权衡
当使用逻辑回归模型时,可更改阈值来权衡精确率和召回率
当阈值提高到0.7,则说明当算法有70%及以上的信心认为样本患病时,才把该样本标记为患病。如果只有69%的信心时,则不标记患病,划分为未患病。
因此,通过提高阈值,可以提高精确度,但是会降低召回率。
如果治疗花费非常高、对患者伤害很大,则可能需要高精确度。反之,如果花费不是很高,伤害也小,但是不治疗会带来更糟糕的后果,则可能需要高召回率。
F1 Score,用于自动结合精确度和召回率,以帮助你选择最佳算法或最佳权衡两者。更强调的是这些值中较低的那个。数值较大的算法较好
种结合P和R精度和召回率的方法,但它更强调这些值中较低的那个